Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Retrieval-augmented generation (RAG) has become a popular method for grounding large language models (LLMs) in external knowledge. RAG systems typically use an embedding model to encode documents in a knowledge corpus and select those that are most relevant to the user’s query.
However, standard retrieval methods often fail to account for context-specific details that can make a big difference in application-specific datasets. In a new paper, researchers at Cornell University introduce “contextual document embeddings,” a technique that improves the performance of embedding models by making them aware of the context in which documents are retrieved.
The limitations of bi-encoders
The most common approach for document retrieval in RAG is to use “bi-encoders,” where an embedding model creates a fixed representation of each document and stores it in a vector database. During inference, the embedding of the query is calculated and compared to the stored embeddings to find the most relevant documents.
Bi-encoders have become a popular choice for document retrieval in RAG systems due to their efficiency and scalability. However, bi-encoders often struggle with nuanced, application-specific datasets because they are trained on generic data. In fact, when it comes to specialized knowledge corpora, they can fall short of classic statistical methods such as BM25 in certain tasks.
“Our project started with the study of BM25, an old-school algorithm for text retrieval,” John (Jack) Morris, a doctoral student at Cornell Tech and co-author of the paper, told VentureBeat. “We performed a little analysis and saw that the more out-of-domain the dataset is, the more BM25 outperforms neural networks.”
BM25 achieves its flexibility by calculating the weight of each word in the context of the corpus it is indexing. For example, if a word appears in many documents in the knowledge corpus, its weight will be reduced, even if it is an important keyword in other contexts. This allows BM25 to adapt to the specific characteristics of different datasets.
“Traditional neural network-based dense retrieval models can’t do this because they just set weights once, based on the training data,” Morris said. “We tried to design an approach that could fix this.”
Contextual document embeddings
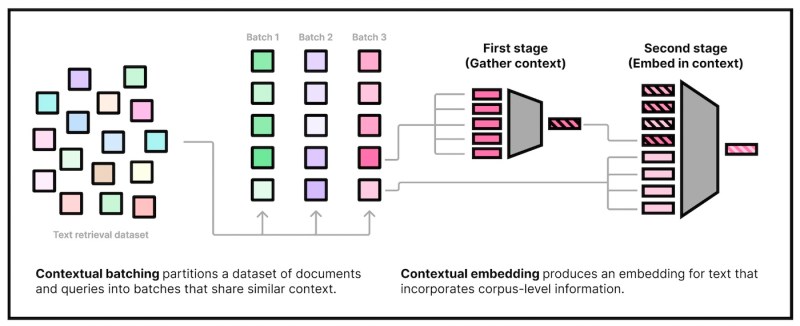
The Cornell researchers propose two complementary methods to improve the performance of bi-encoders by adding the notion of context to document embeddings.
“If you think about retrieval as a ‘competition’ between documents to see which is most relevant to a given search query, we use ‘context’ to inform the encoder about the other documents that will be in the competition,” Morris said.
The first method modifies the training process of the embedding model. The researchers use a technique that groups similar documents before training the embedding model. They then use contrastive learning to train the encoder on distinguishing documents within each cluster.
Contrastive learning is an unsupervised technique where the model is trained to tell the difference between positive and negative examples. By being forced to distinguish between similar documents, the model becomes more sensitive to subtle differences that are important in specific contexts.
The second method modifies the architecture of the bi-encoder. The researchers augment the encoder with a mechanism that gives it access to the corpus during the embedding process. This allows the encoder to take into account the context of the document when generating its embedding.
The augmented architecture works in two stages. First, it calculates a shared embedding for the cluster to which the document belongs. Then, it combines this shared embedding with the document’s unique features to create a contextualized embedding.
This approach enables the model to capture both the general context of the document’s cluster and the specific details that make it unique. The output is still an embedding of the same size as a regular bi-encoder, so it does not require any changes to the retrieval process.
The impact of contextual document embeddings
The researchers evaluated their method on various benchmarks and found that it consistently outperformed standard bi-encoders of similar sizes, especially in out-of-domain settings where the training and test datasets are significantly different.
“Our model should be useful for any domain that’s materially different from the training data, and can be thought of as a cheap replacement for finetuning domain-specific embedding models,” Morris said.
The contextual embeddings can be used to improve the performance of RAG systems in different domains. For example, if all of your documents share a structure or context, a normal embedding model would waste space in its embeddings by storing this redundant structure or information.
“Contextual embeddings, on the other hand, can see from the surrounding context that this shared information isn’t useful, and throw it away before deciding exactly what to store in the embedding,” Morris said.
The researchers have released a small version of their contextual document embedding model (cde-small-v1). It can be used as a drop-in replacement for popular open-source tools such as HuggingFace and SentenceTransformers to create custom embeddings for different applications.
Morris says that contextual embeddings are not limited to text-based models can be extended to other modalities, such as text-to-image architectures. There is also room to improve them with more advanced clustering algorithms and evaluate the effectiveness of the technique at larger scales.
READ SOURCE








