Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
Researchers at Together AI and Agentica have released DeepCoder-14B, a new coding model that delivers impressive performance comparable to leading proprietary models like OpenAI’s o3-mini.
Built on top of DeepSeek-R1, this model gives more flexibility to integrate high-performance code generation and reasoning capabilities into real-world applications. Importantly, the teams have fully open-sourced the model, its training data, code, logs and system optimizations, which can help researchers improve their work and accelerate progress.
Competitive coding capabilities in a smaller package
The research team’s experiments show that DeepCoder-14B performs strongly across several challenging coding benchmarks, including LiveCodeBench (LCB), Codeforces and HumanEval+.
“Our model demonstrates strong performance across all coding benchmarks… comparable to the performance of o3-mini (low) and o1,” the researchers write in a blog post that describes the model.
Interestingly, despite being trained primarily on coding tasks, the model shows improved mathematical reasoning, scoring 73.8% on the AIME 2024 benchmark, a 4.1% improvement over its base model (DeepSeek-R1-Distill-Qwen-14B). This suggests that the reasoning skills developed through RL on code can be generalized effectively to other domains.
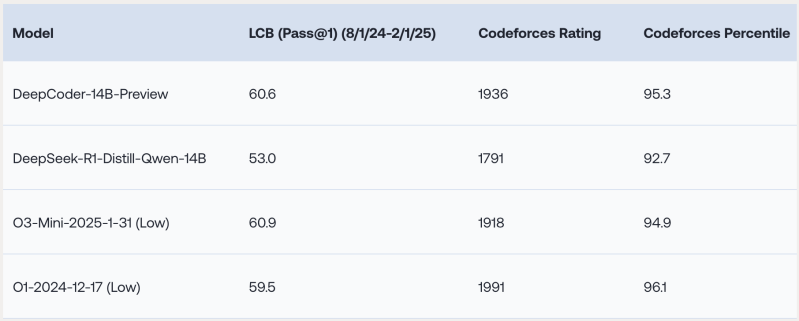
The most striking aspect is achieving this level of performance with only 14 billion parameters. This makes DeepCoder significantly smaller and potentially more efficient to run than many frontier models.
Innovations driving DeepCoder’s performance
While developing the model, the researchers solved some of the key challenges in training coding models using reinforcement learning (RL).
The first challenge was curating the training data. Reinforcement learning requires reliable reward signals indicating the model’s output is correct. As the researchers point out, “Unlike math—where abundant high-quality, verifiable data is readily available on the Internet—the coding domain suffers from a relative scarcity of such data.”
To address this problem, the DeepCoder team implemented a strict pipeline that gathers examples from different datasets and filters them for validity, complexity and duplication. This process yielded 24,000 high-quality problems, providing a solid foundation for effective RL training.
The team also designed a straightforward reward function that only provides a positive signal if the generated code passes all sampled unit tests for the problem within a specific time limit. Combined with the high-quality training examples, this outcome-focused reward system prevents the model from learning tricks like printing memorized answers for public tests or optimizing for simple edge cases without solving the core problem.
The model’s core training algorithm is based on Group Relative Policy Optimization (GRPO), a reinforcement learning algorithm that proved very successful in DeepSeek-R1. However, the team made several modifications to the algorithm to make it more stable and allow the model to continue improving as the training extends for a longer time.
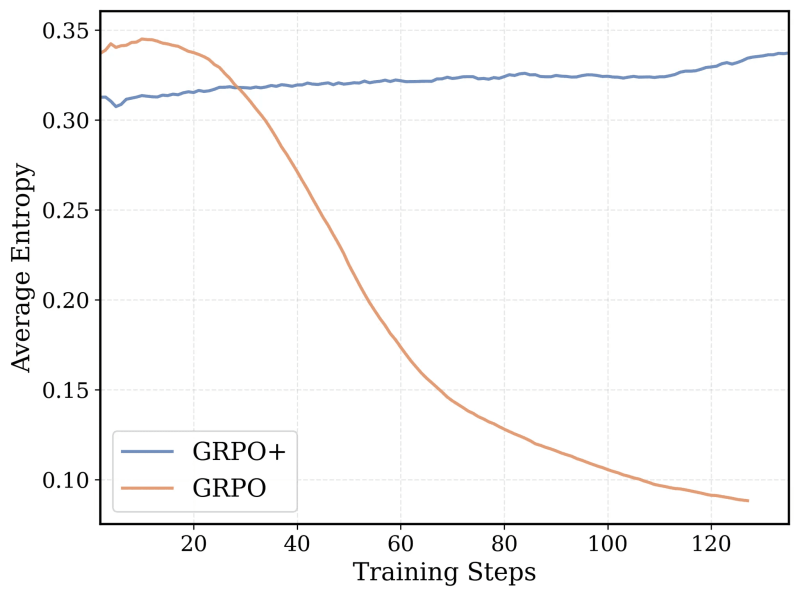
Finally, the team extended the model’s context window iteratively, first training it on shorter reasoning sequences and gradually increasing the length. They also developed a filtering method to avoid penalizing the model when it created reasoning chains that exceeded the context limits when solving a hard prompt.
The researchers explain the core idea: “To preserve long-context reasoning while enabling efficient training, we incorporated overlong filtering… This technique masks out truncated sequences during training so that models aren’t penalized for generating thoughtful but lengthy outputs that exceed the current context limit.”
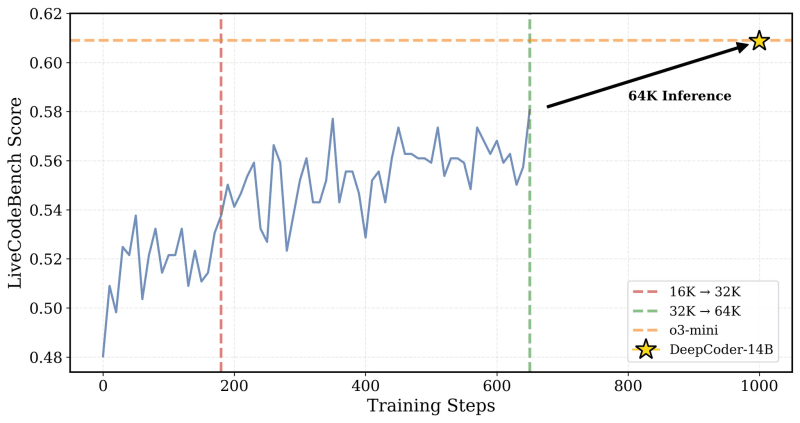
The training was gradually scaled from a 16K to a 32K context window, and the resulting model could also solve problems that required up to 64K tokens.
Optimizing long-context RL training
Training large models with RL, especially on tasks requiring long generated sequences like coding or complex reasoning, is computationally intensive and slow. A major bottleneck is the “sampling” step, where the model generates potentially thousands of tokens per example in the batch. Variations in response length mean some responses finish much later than others, leaving GPUs idle and slowing down the entire training loop.
To accelerate this, the team developed verl-pipeline, an optimized extension of the open-source verl library for reinforcement learning from human feedback (RLHF). The key innovation, which they call “One-Off Pipelining,” rearranges the response sampling and model updates to reduce the bottlenecks and accelerator idle time.
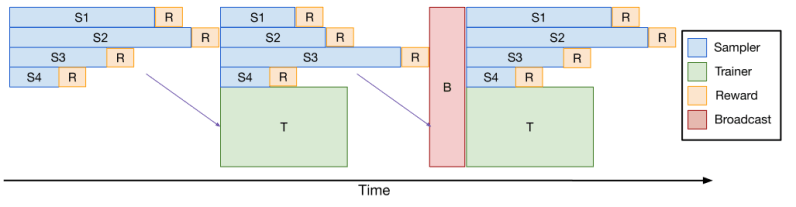
Their experiments showed that one-off pipelining provided up to a 2x speedup for coding RL tasks compared to baseline implementations. This optimization was crucial for training DeepCoder within a reasonable timeframe (2.5 weeks on 32 H100s) and is now open-sourced as part of verl-pipeline for the community to use and build upon.
Enterprise impact
The researchers have made all the artifacts for training and running DeepCoder-14B available on GitHub and Hugging Face under a permissive license.
“By fully sharing our dataset, code, and training recipe, we empower the community to reproduce our work and make RL training accessible to all,” the researchers write.
DeepCoder-14B powerfully illustrates a broader, accelerating trend in the AI landscape: the rise of highly capable yet efficient and openly accessible models.
For the enterprise world, this shift signifies more options and higher accessibility of advanced models. Cutting-edge performance is no longer solely the domain of hyperscalers or those willing to pay premium API fees. Models like DeepCoder can empower organizations of all sizes to leverage sophisticated code generation and reasoning, customize solutions to their specific needs, and securely deploy them within their environments.
This trend can lower the barrier to entry for AI adoption and foster a more competitive and innovative ecosystem, where progress is driven through open source collaboration.

READ SOURCE








