Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More
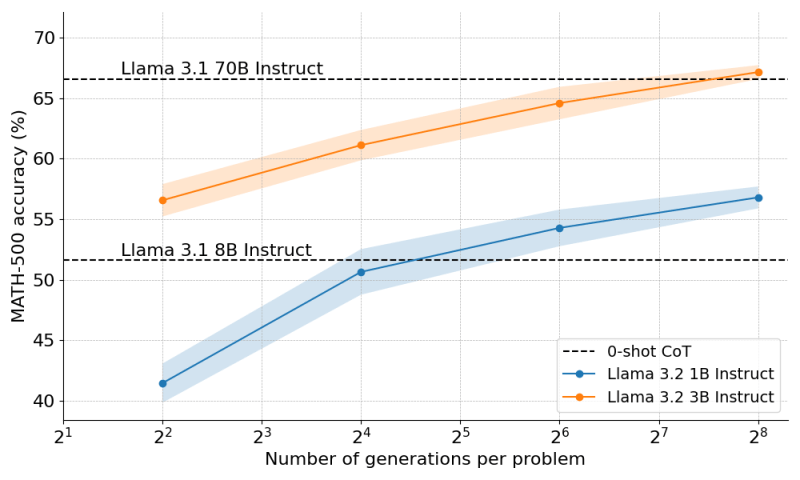
In a new case study, Hugging Face researchers have demonstrated how small language models (SLMs) can be configured to outperform much larger models. Their findings show that a Llama 3 model with 3B parameters can outperform the 70B version of the model in complex math problems.
Hugging Face has fully documented the entire process and provides a roadmap for enterprises that want to create their own customized reasoning models.
Scaling test-time compute
The work is inspired by OpenAI o1, which uses extra “thinking” to solve complex math, coding and reasoning problems.
The key idea behind models like o1 is to scale “test-time compute,” which effectively means using more compute cycles during inference to test and verify different responses and reasoning paths before producing the final answer. Scaling test-time compute is especially useful when there is not enough memory to run a large model.
Since o1 is a private model and OpenAI has remained tight-lipped about its internal workings, researchers have been speculating about how it works and trying to reverse engineer the process. There are already several open alternatives to o1.
Hugging Face work is based on a DeepMind study released in August, which investigates the tradeoffs between inference-time and pre-training compute. The study provides comprehensive guidelines on how to balance training and inference compute to get the best results for a fixed budget.
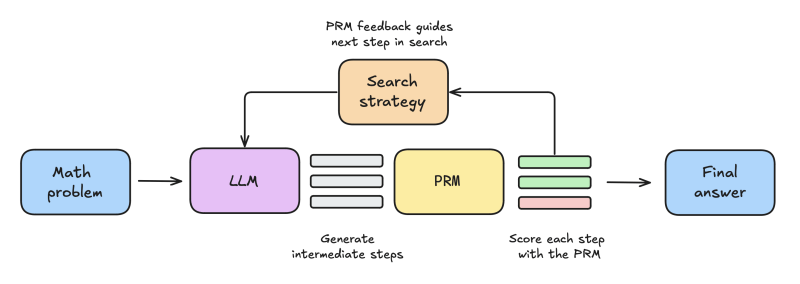
In addition to using extra inference-time compute, the success of the technique hinges on two key components: A reward model that evaluates the SLM’s answers, and a search algorithm that optimizes the path it takes to refine its answers.
Different reasoning algorithms
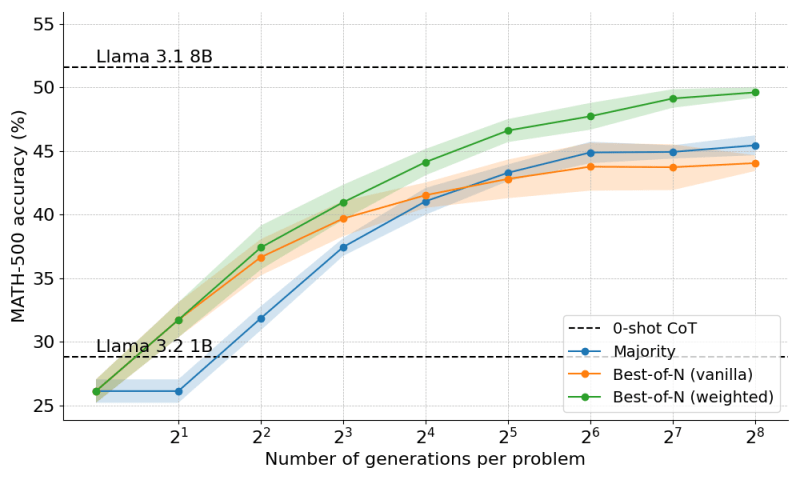
The simplest way to use test-time scaling is “majority voting,” in which the same prompt is sent to the model multiple times and the highest-voted is chosen. In simple problems, majority voting can prove useful, but its gains quickly plateau on complex reasoning problems or tasks where errors are consistent across generations.
A more advanced reasoning method is “Best-of-N.” In this technique, the SLM generates multiple answers, but instead of majority voting, a reward model is used to evaluate the answers and choose the best one. “Weighted Best-of-N,” a more nuanced version of this method, factors in consistency to choose answers that are both confident and occur more frequently than others.
The researchers used a “process reward model” (PRM) that scores the SLM’s response not only on the final answer but also on the multiple stages it goes through to reach it. Their experiments showed that Weighted Best-of-N and PRMs brought the Llama-3.2 1B near the level of Llama-3.2 8B on the difficult MATH-500 benchmark.
Adding search
To further improve the model’s performance, the researchers added search algorithms to the model’s reasoning process. Instead of generating the answer in a single pass, they used “beam search,” an algorithm that guides the model’s answer process step by step.
At each step, the SLM generates multiple partial answers. The search algorithm uses the reward model to evaluate the answers and chooses a subset that is worth further exploring. The process is repeated until the model exhausts its inference budget or reaches the correct answer. This way, the inference budget can be narrowed to focus on the most promising answers.
The researchers found that while beam search improves the model’s performance on complex problems, it tends to underperform other techniques on simple problems. To address this challenge, they added two more elements to their inference strategy.
First was Diverse Verifier Tree Search (DVTS), a variant of beam search that ensures that the SLM doesn’t get stuck in false reasoning paths and diversifies its response branches. Secondly, they developed a “compute-optimal scaling strategy,” as suggested in the DeepMind paper, which dynamically chooses the best test-time scaling strategy based on the difficulty of the input problem.
The combination of these techniques enabled Llama-3.2 1B to punch above its weight and outperform the 8B model by a significant margin. They also found that the strategy was scalable, and when applied to Llama-3.2 3B, they were able to outperform the much larger 70B model.

Not a perfect solution yet
Scaling test-time compute changes the dynamics of model costs. Enterprises now have the ability to choose where to allocate their compute resources. For example, if you are short on memory or can tolerate slower response times, you can use a small model and spend more inference-time cycles to generate more accurate answers.
However, test-time scaling also has its limitations. For example, in the experiments carried out by Hugging Face, researchers used a specially trained Llama-3.1-8B model as the PRM, which requires running two models in parallel (even if it is much more resource-efficient than the 70B model). The researchers acknowledge that the holy grail of test-time scaling is to have “self-verification,” where the original model verifies its own answer as opposed to relying on an external verifier. This is an open area of research.
The test-time scaling technique presented in this study is also limited to problems where the answer can be clearly evaluated, such as coding and math. Creating reward models and verifiers for subjective tasks such as creative writing and product design requires further research.
But what is clear is that test-time scaling has generated a lot of interest and activity and we can expect more tools and techniques to emerge in the coming months. Enterprises will be wise to keep an eye on how the landscape develops.

READ SOURCE









